OCR、Googleドライブを使った文字起こし


OCRの歴史
OCR(Optical Character Recognition:光学的文字認識)とは、手書きの文章や印刷された文章をスキャナやカメラを通してデジタル化し、コンピュータが認識できる文字データに変換する技術のことをさします。
人間が文字を読むように、映像や画像からそのままコンピュータに文字を読ませるということはまだ技術的には不可能とされていますが、OCRのように人間とコンピュータ間の処理の差を補う手段は少しずつ実用化されています。特に最近はAI技術の発達により、その実用レベルは著しく向上しています。

OCRの歴史は古く、1914年にOCRの原型といえる機械も出現しており、1930年頃にはOCRの特許も取得されていました。
単純な数字などの読み取り処理はパソコンが生まれるもっと以前から実用化されており、アメリカでは報告書や請求書などを自動で読み取るための機械が1950年代から利用されています。
日本でも郵便番号を自動的に仕分けするための機械として、1968年に東芝が国産のOCRを製品化しています。
OCR機能を利用するメリットとしては、大量の情報を手動で入力する必要がなく自動的にデータ化ができるということです。データ化することで分別・集計や、訂正・編集も容易になり、特に検索作業の大幅な効率化がはかれます。また紙媒体の文書を保管するには物理的なスペースが必要となりますが、データ化することで保管場所の節約もできます。
文字認識の流れ
ドットの集まりでしかない黒いシミを文字として認識し、それを区分するにはどうすればいいのでしょうか。
OCRが実際に動作する際の基本的な流れを簡単に解説します。
1.事前処理
読み取りした画像の傾きや歪みの補正、汚れ除去などの微調整を施し、次に罫線や背景などとテキストブロックの分離が行われます。
どの辺りが文字の部分なのかの大まかな当たりをつけた後に、さらに単語単位、文字単位で区切りをつけて識別をすすめていきます。
2.文字認識
次に文字らしきものを具体的な文字として認識させます。
複数のアルゴリズムを組み合わせてどの文字になるのかを比較させます。マトリックスマッチングのように主成分を抽出して比較する方法や、線の方向や交差の部分などの特徴だけを検出する方法などが使われます。
例えば「め」と「ぬ」などのまぎらわしい文字は、どこがどう違ったら違うことになるのか、その特徴を見極めるためのステップです。少しでも検出力と効率を上げるため、様々なアルゴリズムが開発されてきましたが、最近では機械学習が利用されることになり、よりスムーズにそして強力になってきました。
3.事後処理
最後の事後処理として、読み取った文字は実際に存在している単語なのかを辞書を使って精度を上げることもあります。また読み取りにくい部分でも近傍分析のアルゴリズムを活用することで、前後の単語から識別がつくこともあります。
機械学習による文字認識
昨今のAI認識の急激な進歩のきっかけとなった出来事として「Googleの猫」という事例があげられます。
これは2012年にAI界に衝撃を与えたニュースで、Google社が「人が教えることなく、AIが自発的に猫を認識することに成功した」と公表した件です。
具体的な内容としては、ディープラーニングという手法を用いて、Youtubeに投稿されたビッグデータの中から、無作為に一千万枚の画像を取り出してAIに繰り返し学習を実施することで、ある画像をみてそれが猫であるかないか、猫とは何であるかを画像で示すことができるようになったのです。
※AIが示した猫の画像も下記サイトで参照できます。
人がプログラム的に猫を定義して教えたのではなく、猫の画像を大量に見せるだけで、猫とはどんなものなのかを独自に定義付できたということでAIが新しい段階に進化したことを世界に披露しました。
これはつまり、従来の方式では区別をつけることが難しかった、例えば雑に手書きされた「め」と「ぬ」などの違いも、人間側が個別に事前に見分け方を教えなくてもAIが独自に学習をして見分けられるようになることを示しています。
Googleドライブを利用したOCRについて
Google社のサービスの一つに、無料オンラインストレージであるGoogleドライブがあります。
その機能の一つにアップロードしたファイルに対してのOCRのサービスも組み込まれています。気軽に使えるサービスなのでOCRを試してみたい方は参考にしてみてください。
実際に「注文の多い料理店」宮澤賢治(著)の文章をOCRで読み込んでみます。


-
以下のリンクにアクセスしご自身のGoogleアカウントでログインする。
https://www.google.com/intl/ja_jp/drive/ -
GoogleDrive に文字データ化したい画像をアップロードする
「新規ボタン」をクリックし「ファイルのアップロード」ボタンから追加できます。 -
アップロードした画像上で右クリック → アプリで開く → Googleドキュメントアプリを選択
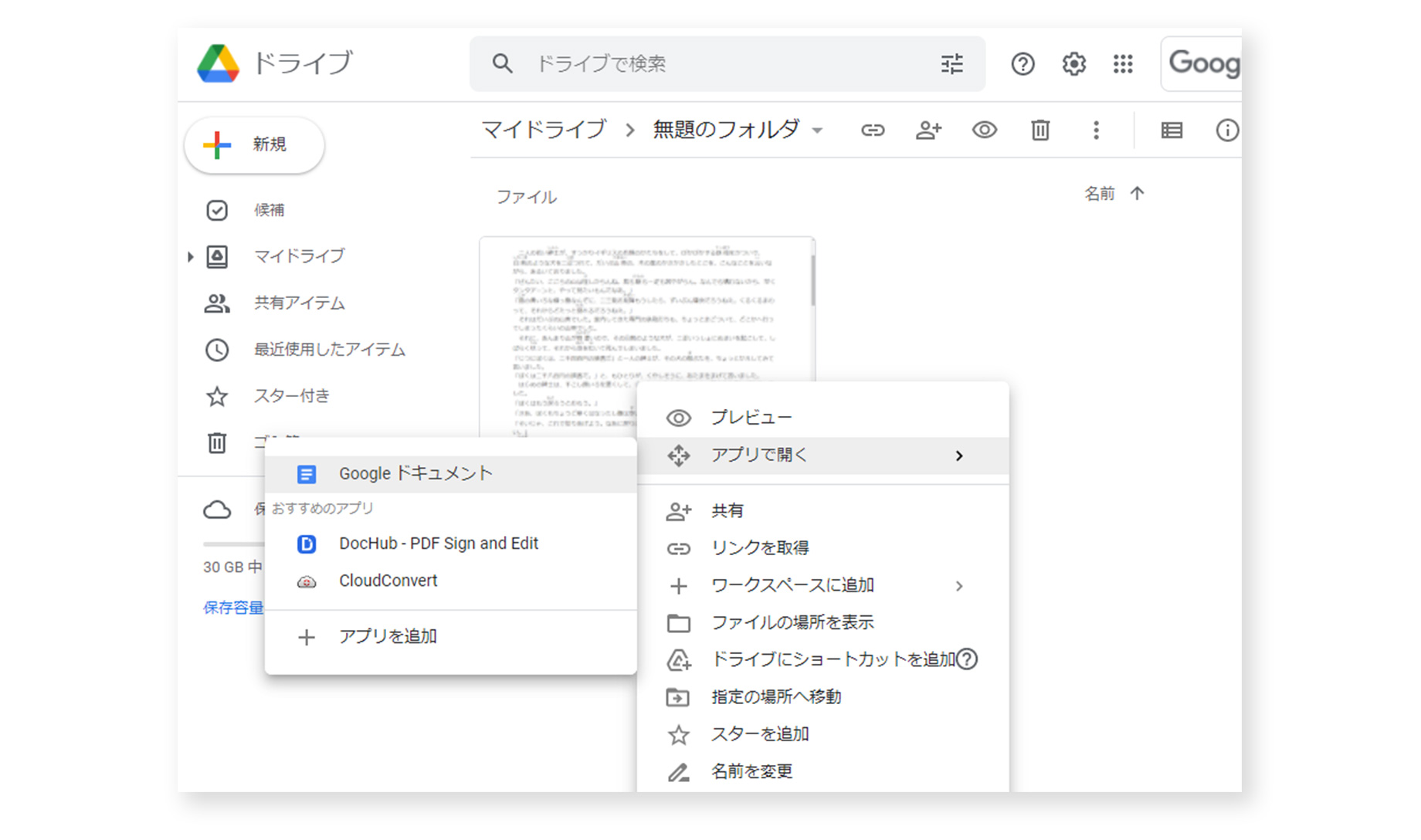
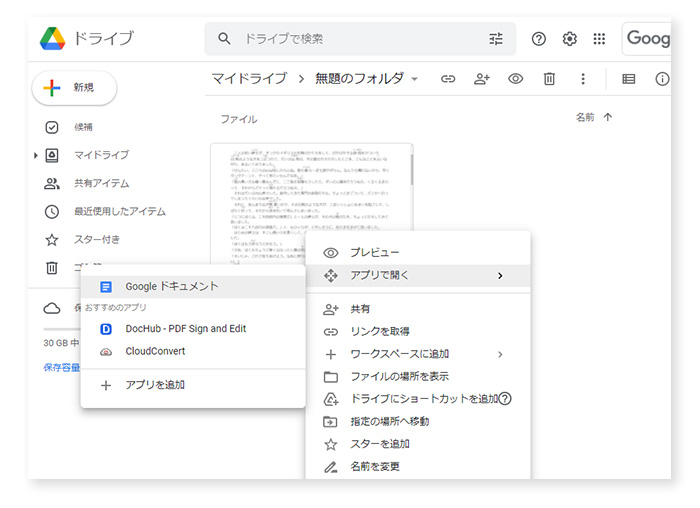
[GoogleDrive上の操作画面] - 処理が完了するまでしばらく待ちます。
- テキストデータが出力されます。以上で作業は完了です。
以下のようにデータが出力されます。


上部にオリジナルの画像ファイルが表示され、その下に変換したテキストデータが出力されます。
サンプルは約900文字の文章ですがミスは2~3%程度で収まっています。印刷した文書であれば、読み取りの精度に関しては文句ない物に仕上がることでしょう。
以上が簡単な手順で出来るOCRによるテキスト化の手順となります。
Google公式が推奨しているアップロードする際の画像の要件は以下となります。
- 形式:JPEG、PNG、GIF、PDFの各ファイル。
- サイズ:ファイルは2MBまで
- 解像度:テキストの高さは10ピクセル以上
注意点としてファイル内にイラストや写真などが含まれていると、正常に認識できないことがあります。イラスト内に表示されているテキストを文字として読み取る場合はありますが、イラストそのものはOCR上では無視されるので注意が必要です。
また手書きの文字データも同様の手順で対応は可能ですが、印刷した文字に比べて精度は決して高くありません。OCRで取り込んだ文字起こしのデータの精度が低く、どうしても品質を上げたいご要望があるようでしたら、商用のOCRであれば適切な設定をすることで手書き文字などにも高い精度で対応が可能です。わざわざ購入して対応するほどではないということでしたら、文字起こしの校正などをサポートする弊社の「文字起こしデータ校正サービス」のご利用をご検討ください。
このようなAIを活用した文字認識や文字起こしのサービスは、まずは標準言語である英語から発展してきましたが、日本語への対応も徐々に増えてきています。
文字認識の精度に関してはまだ人間には遠く及びませんが、今後AIの進歩によりますます機能が向上していくと考えられており、現在人間が行っている仕事の大部分はAIにとって代わられるかもしれません。

音声・動画データの文字起こしが必要な時
データグリーンなら
特に日本語に関してはAIによる音声認識、文字起こしは完全でないのが現状です。テキスト化した後も、句読点の付与、誤変換の修正、フィラーワードの削除(ケバ取り)などの確認・修正作業も欠かせません。データグリーンでは、音声データの解析技術と熟練ライターの豊富な経験・ノウハウを組み合わせた「精度の高い文字起こし」を提供しております。
AI音声認識では対応できない録音環境が悪いデータ、声が遠い(小さい)データ、活舌が悪く早口だったり話者の人数が多く会話が被っているデータ、専門性の高い音声等、長時間の文字起こしにも低価格で対応可能です。プライバシーマークおよび情報セキュリティマネジメントシステム「ISO27001(ISMS)」の認証も取得しておりますので、秘匿性、機密性の高い音声データの文字起こし、テープ起こしもおまかせください。