音声認識と文字起こし


音声認識とは
音声認識とは、人間が発した音声をコンピュータに認識させ、解析し文字(テキストデータ)に変換、あるいは操作させる技術をいいます。
現在では、AI技術の進化により、Androidに搭載されているGoogleアシスタントやiPhoneのSiriでは、音声によって操作ができるようになり、スマートスピーカーを利用すれば、様々な家電製品を操作することも可能になってきました。
また、会議の議事録や動画の字幕作成、コールセンターなどの顧客からの問い合わせ内容の書き起こしなど、音声認識は幅広い分野で利用されています。

音声認識の歴史
音声認識の歴史は古く、1950年代から始まります。当初は、数字(0~9)を認識できる程度のものでしたが、1962年にはIBMが世界初の音声認識システム「Shoebox」を発表しました。これは0~9の数字とプラスやマイナスといった6種類の計算コマンドを認識でき、音声で単純な算術ができるシステムでした。靴箱程度の大きさだったから「Shoebox」と名付けられたそうです。

(IBM Archives > ExhibitsIBM > special products(vol. 1))
また日本でも同じく1962年に京都大学において、単音節(「あ」や「い」など)の声を認識する「音声タイプライタ」が発表されています。この時代はコンピュータで何ができるかを科学者が競い合っていた時代で、第一次AIブームと呼ばれています。
1960年代までは、単音節の認識しかできませんでしたが、技術の進歩により1970年代には、単語間での音声認識、1980年代には、文章としての認識が可能となります。
専門家の判断能力をエミュレートするAIプログラム(エキスパートシステム)が商用利用されるようになった時代で第二次AIブームと呼ばれています。
その後1990年~2000年代に入ると、カーナビや「シーマン」のようなテレビゲーム等にも音声認識が使われるようになります。
なおシーマンについては、当時の技術でよくあれほどの会話演出が可能だったと振り替えられることがあるそうですが「実のところ、最初のバージョンのシーマンの会話には、大した技術など使われていない。膨大な会話の分岐と組み合わせ」に過ぎず、人工知能(AI)などは使われていなかったそうです。
そして2000年代から現在にかけて、第三次AIブームが起こります。コンピュータ技術の進化が、より実践的な機械学習・ディープラーニング・ビッグデータを普及、活用させることを可能にし、音声認識の技術も著しく進歩しました。スマホや生活家電といった我々の身近にある製品で実用的な音声操作をすることが可能となっています。
音声認識の仕組み
コンピュータは普段人が行っているように音声をそのまま理解することはできません。
どのような流れでコンピュータに認識させるのか、ディープランニングを用いない仕組みを例に解説します。
大雑把な流れとしては以下の通りです。
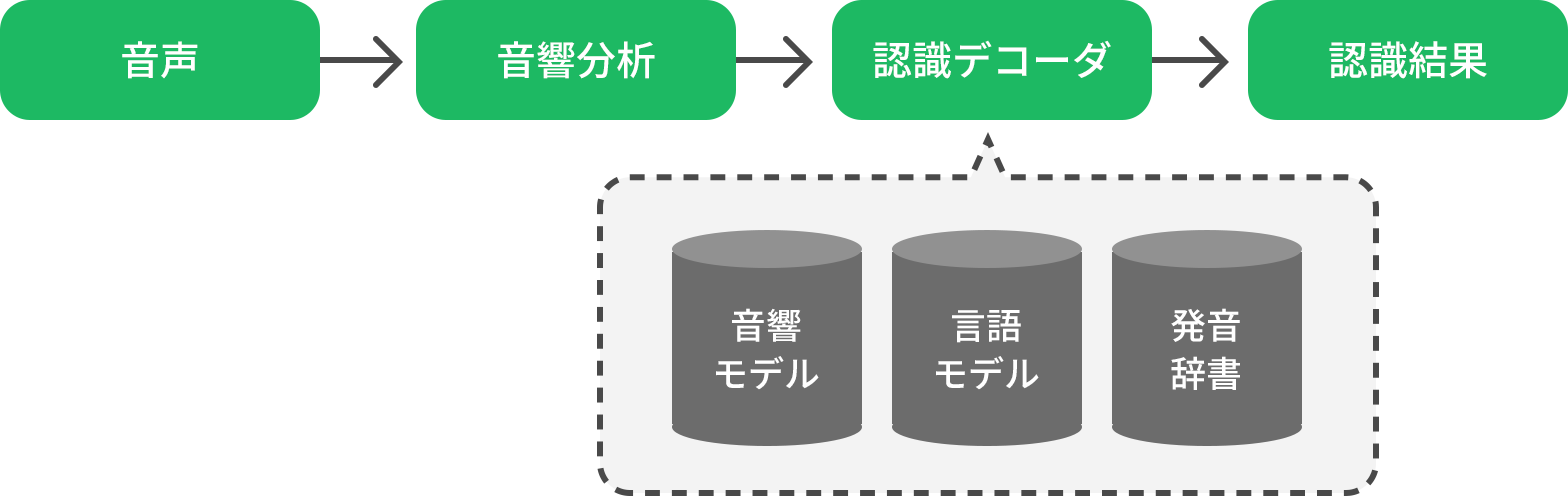
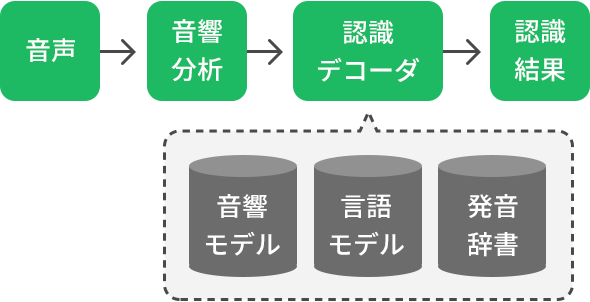
まず取り込んだ音声を音響分析によって波形に変換し、コンピュータが理解できやすいようにデータ化します。次に、音素を抽出する音響モデル、単語や品詞を出現する確率から推論していく言語モデル、音素を単語化して辞書とパターンマッチングさせる発音辞書という3つのモジュールを組み合わせて、テキストデータとして出力します。
これらの処理のことをデコード、もしくはデコーディングと呼びます。エンコードするというのが符号化、あるいは暗号化することで、逆に解読することがデコードです。例えるとインスタントラーメンのように水分を抜いてパリパリにすることがエンコードで、お湯をかけて食べられる状態にするのがデコードになります。

-
音声入力
認識したい音声を、マイクなどで直接入力または、音声データを取り込みます。
-
音響分析
音声(アナログ信号)から周波数や音の強弱を抽出し、コンピュータが認識しやすい波形データ(デジタル信号)に変換します。
-
音響モデル
データに変換した音声から、音素を抽出します。音素とは、音声を発生したときに確認できる最小の単位を表し、日本語では、「母音、子音、撥音(ン)」の組み合わせで構成されます。
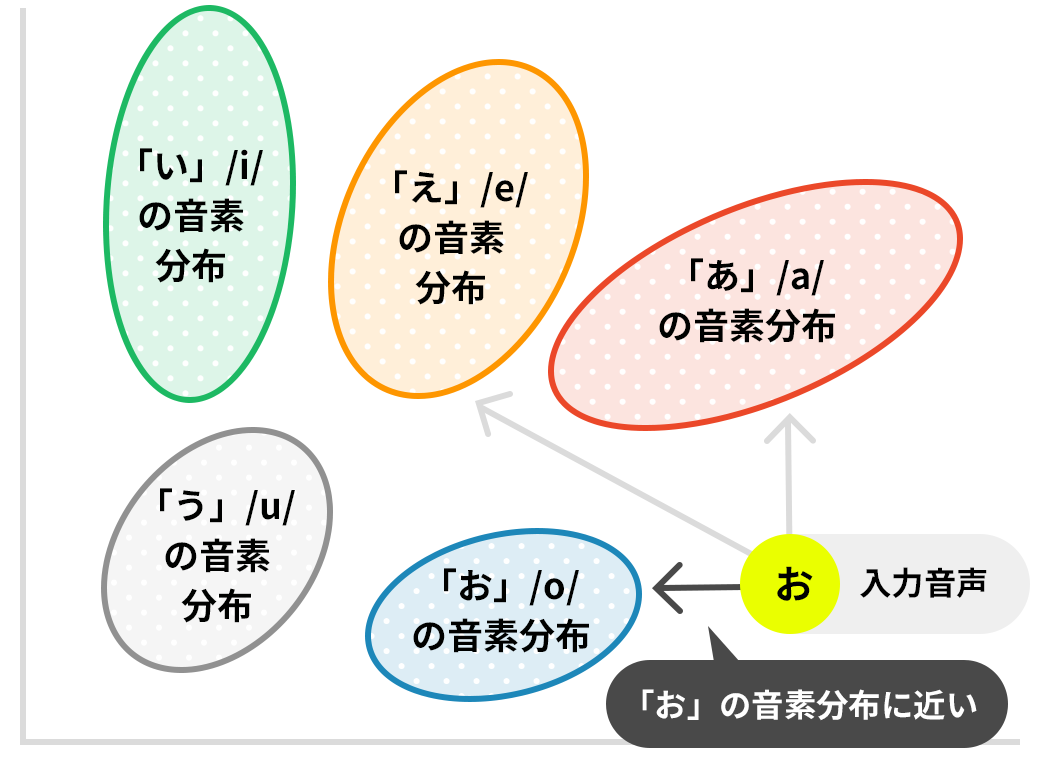
音響モデルでは、入力された音声がどの音素に近いかを計算します。
入力された音声が「おはよう」の場合、「o-h-a-y-o-u」という音素が抽出されます。 -
発音辞書によるパターンマッチ
音響モデルによって音素を抽出したあとは、発音辞書により単語として変換します。例えば、音素が「o-h-a-y-o-u」であれば「おはよう」、「a-r-i-g-a-t-o-u 」の場合は「ありがとう」のようにアルファベットの羅列を日本語として読めるように変換します。
-
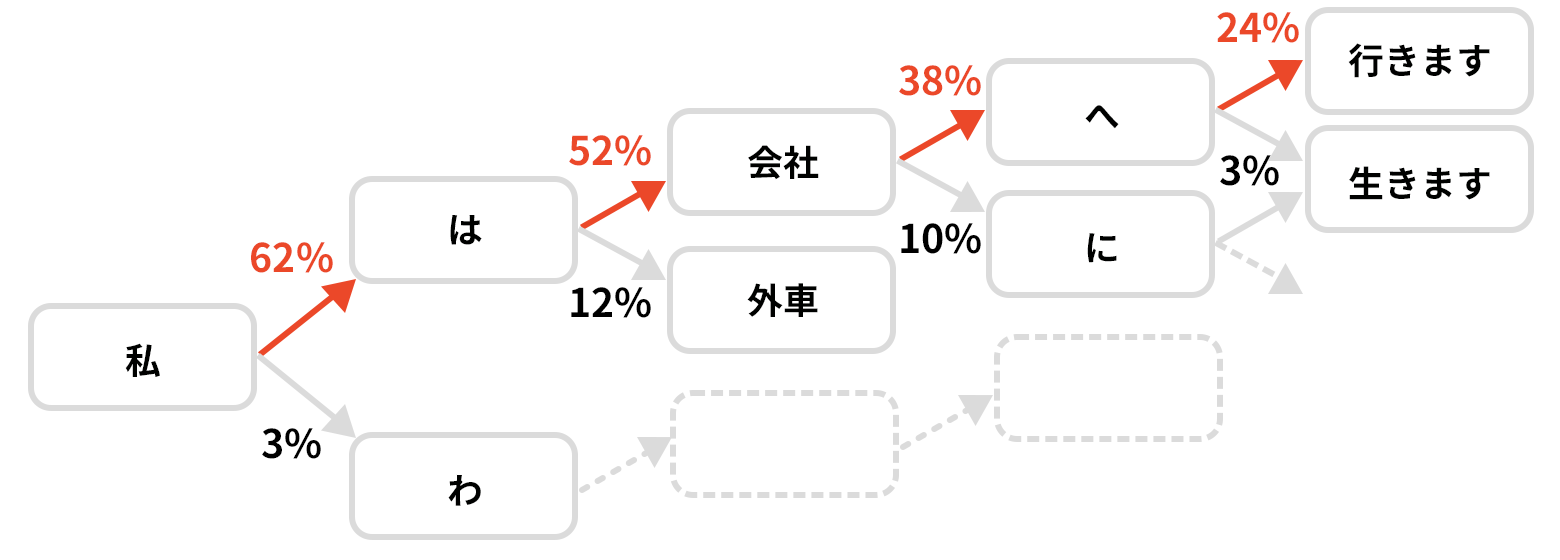
言語モデル
言語モデルでは、単語間のつながりを予測判定し、日本語の文章として組み立てを行います。大量の日本語テキストデータから言語モデルを作成し、ある単語から、次に来る単語を確率から予測し、日本語の文章として整形化します。
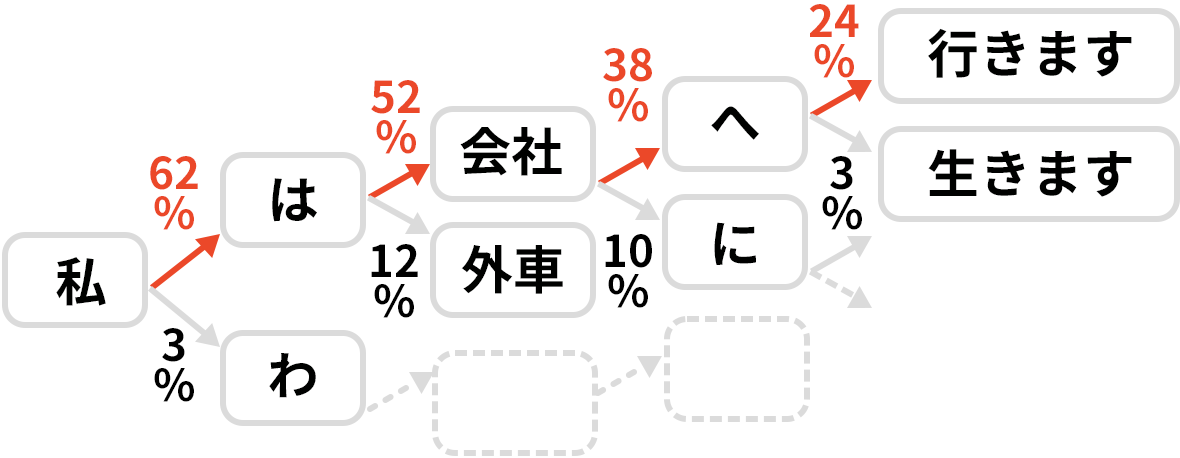
-
認識結果を出力
音声を音素から単語、単語から文章に変換する工程を経て、認識結果をテキストデータとして出力します。
音声認識の限界
現在の手法では、上記のモデルにさらにディープランニングと併用することで精度が非常にあがっています。ただしどうしても限界・苦手とされる分野があり、3つのモジュールを阻害しやすいケースでは途端に認識精度が悪くなります。
例えば、雑音やノイズが多い環境、あるいは複数人が同時に発言する環境で録音された音声は、特徴がつかめないため音響モデルでの正確な抽出ができなくなります。また業界特有の言い回しや専門用語、あるいは方言や独特の若者・ギャル言葉などは、サンプリングがほとんどないため、発音辞書によりマッチングや言語モデルでの解析・予測がしにくくなるという弱点があります。
対策として、ノイズ等の環境対策、録音時の音声データの品質を上げるためのテクニックについては下記ページで紹介していますので参考にしてください。
精度の高い音声・動画データの文字起こしが必要な時
音声認識を利用した文字起こしで対応ができない場合、あるいはもっと精度の高い音声・動画データの文字起こしが必要な時はデータグリーンのサービスをご利用ください。 AIによる音声データの解析技術と熟練ライターの豊富な経験・ノウハウを組み合わせた「精度の高い文字起こし、テープ起こし」をご提供できます。音質が悪いデータや長時間の文字起こしにも低価格で対応しており、プライバシーマークおよび情報セキュリティマネジメントシステムの国際規格「ISO27001(ISMS)」の認証も取得しておりますので、秘匿性、機密性の高い音声データの文字起こし、テープ起こしもおまかせください。